LLaMAFactory微调DeepSeek-R1-Distill-Qwen-7B蒸馏模型
1. 安装LLaMA Factory
首先,拉取LLaMA-Factory项目到DSW实例。
sudo git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
接着,我们安装LLaMA-Factory依赖环境。
%cd LLaMA-Factory
sudo pip install -e ".[torch,metrics]"
发现出现环境冲突,使用 pip install --no-deps -e . 解决
sudo pip install --no-deps -e .
运行如下命令,如果显示llamafactory-cli的版本,则表示安装成功。
sudo llamafactory-cli version2. 原模型对话
2.1 启动Web UI
做好前序准备工作后,直接运行下述命令就可以启动Web UI。这里用到的环境变量解释如下:
USE_MODELSCOPE_HUB设为1,表示模型来源是ModelScope。使用HuggingFace模型可能会有网络问题。
点击返回的URL地址,进入Web UI页面。
sudo export USE_MODELSCOPE_HUB=1 && \
llamafactory-cli webui2.2 将模型下载到本地(推荐,可选)
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B2.3 加载原模型,进行对话
在 Web UI 中,选择合适的模型(如 DeepSeek-R1-7B-Distill)并配置对话模板(如 deepseek3)。输入内容后,模型会逐字生成回应,开始进行简单的对话。
如果将模型下载到了本地,更改模型路径为 ~/.cache/modelscope/hub/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/
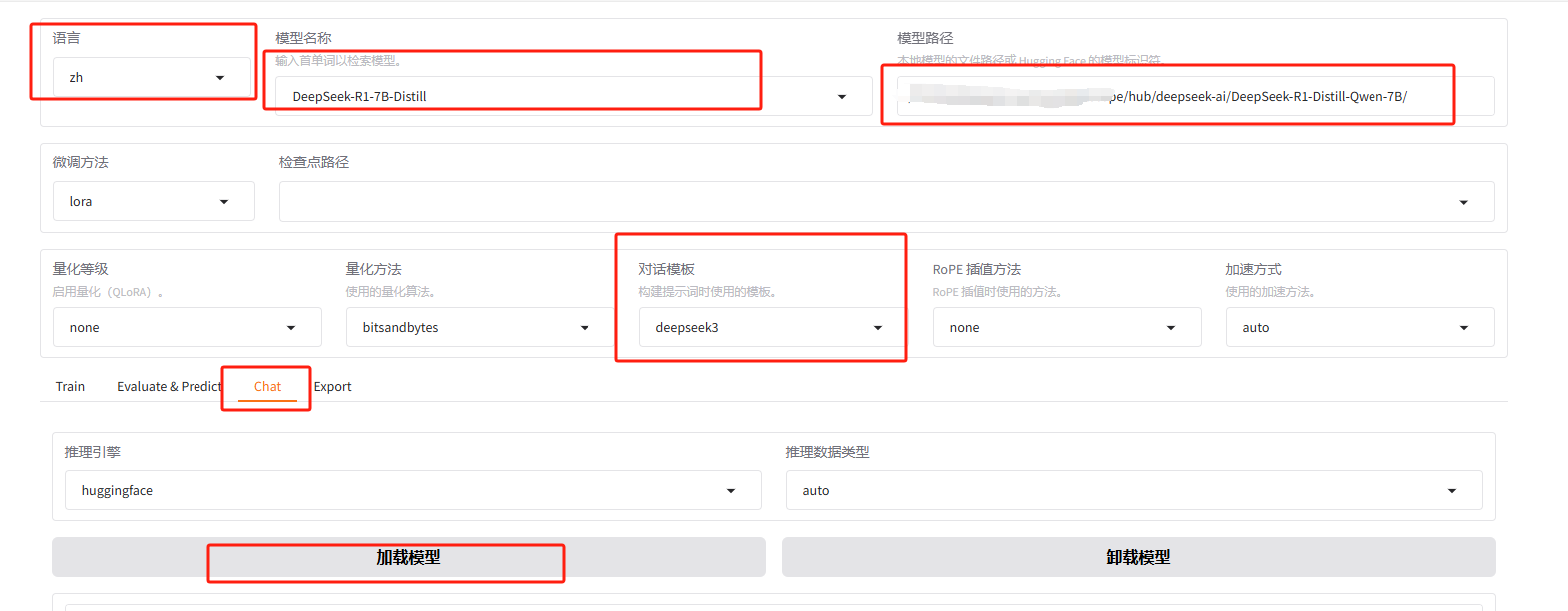
可以进行对话。
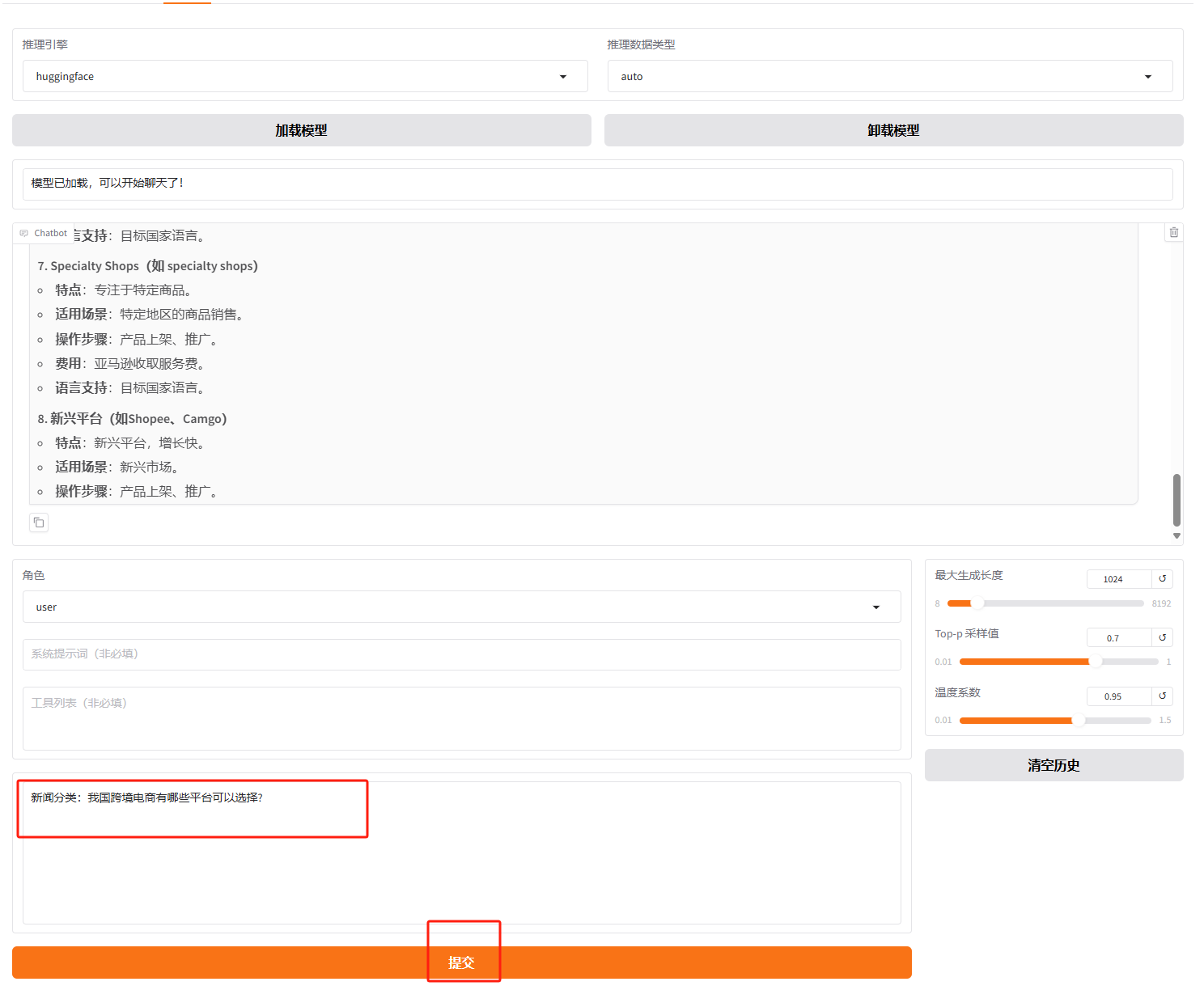
完成对话后,记得点击“卸载模型”以释放显存,准备进行微调。

现在我们准备数据集对模型进行微调,看能否达到想要的效果。
3. 下载数据集
LLaMAFactory 提供了多种数据集,你也可以使用自定义数据集。为了进行新闻分类微调,本教程使用了一个包含 300 条对话样本的数据集:
sudo wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/llama_factory/data_news_300.zip
sudo unzip data_news_300.zip
该数据集包含新闻标题及其对应的分类(如:政治、经济、科技、娱乐等)。每个对话样本由两部分组成:输入新闻标题和 GPT 模型生成的分类。
数据样例如下:
[
{
"conversations": [
{
"from": "human",
"value": "新闻分类:给力!中国两次出手,美到手的订单黄了,该国从此只认中国制造!"
},
{
"from": "gpt",
"value": "<think>\n首先,我需要分析给出的新闻标题:“给力!中国两次出手,美到手的订单黄了,该国从此只认中国制造!”\n\n接下来,根据标题内容进行分类。标题中提到了中国两次行动导致美国订单出现问题,并且其他国家开始依赖中国制造,说明这涉及国家之间的经济合作和社会影响。\n\n结合新闻种类,考虑到涉及国际贸易和经济合作,最合适的分类是“经济”。所以,这条新闻应该归类到“经济”类别中。\n</think>\n\n经济"
}
]
},
{
"conversations": [
{
"from": "human",
"value": "新闻分类:澳大利亚旅游"
},
{
"from": "gpt",
"value": "<think>\n好吧,我现在要分析这条新闻标题“澳大利亚旅游”属于哪个类别。首先,标题提到的是澳大利亚旅游,所以它和旅游相关。接下来,我需要看看新闻种类里有没有相关的类别。新闻种类包括政治、经济、科技、娱乐、体育、教育、健康、国际、国内、社会,以及旅游。\n\n根据知识储备,旅游本身就属于其中一个类别,可能属于社会或娱乐,但通常旅游更具体,可能单独作为一个类别。不过在这份分类中,并没有独自一个旅游的类别,可能需要看看有没有更合适的。比如,如果列举的是旅游,可能属于社会,因为旅游涉及到人们的生活方式和社会活动。\n\n再想一下,可能“旅游”不太明显属于哪一个大类,可能需要归类到社会中。或者,在给定的选项中,可能没有明确的旅游类别,所以可能需要根据其他因素来判断。假设在预定义的分类中,有旅游作为独立类别的话,那就是旅游;如果没有,就放到社会里。\n\n不过根据用户提供的分类,旅游并没有单独作为一个类,所以可能得归类到社会。或者,可能更接近于“国际”或“国内”,因为澳大利亚可能分为国际或国内旅游。但在这份列表里,国际和国内是两个类别,所以“澳大利亚旅游”作为国内的,可能更准确。\n\n再仔细分析,用户提供的新闻类型是国际、国内,所以如果是国内,应该是国内旅游;如果是跨国,比如其他国家的旅游,那就是国际。所以“澳大利亚旅游”属于国内,因为澳大利亚是中国的国内。所以最终归类到“国内”。\n</think>\n\n国内"
}
]
}
]
4. 模型微调
4.1 配置参数
微调方法则保持默认值lora,数据集使用上述下载的train数据文件。

可以点击「预览数据集」。点击关闭返回训练界面。

微调方法:LoRA(低秩适配器)
设置学习率为
5e-6,梯度累积为2,优化拟合效果。在 LoRA 配置中,选择 LoRA+,并将比例设置为 16,提升模型拟合能力。
设置学习率为5e-6,梯度累积为2,有利于模型拟合。

点击LoRA参数设置展开参数列表,设置LoRA+学习率比例为16,LoRA+被证明是比LoRA学习效果更好的算法。在LoRA作用模块中填写all,即将LoRA层挂载到模型的所有线性层上,提高拟合效果。 
4.2 启动微调
在配置好参数后,点击“开始”启动训练。训练进度和损失曲线将在 Web UI 中实时显示,直到显示“训练完毕”表示微调完成。
点击「开始」启动模型微调。 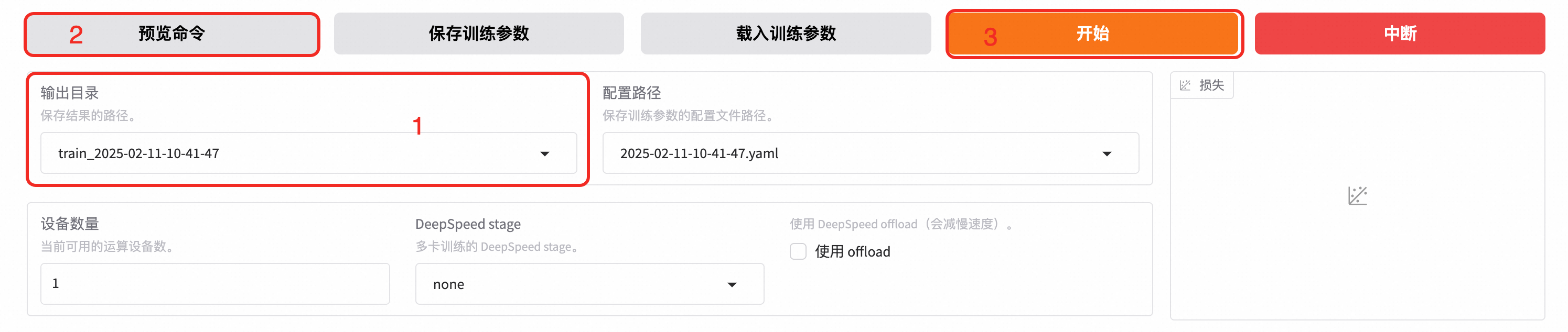
启动微调后需要等待一段时间,待模型下载完毕后可在界面观察到训练进度和损失曲线。显示“训练完毕”代表微调成功。 
5. 模型评估
微调完成后,使用验证集对模型进行评估。 
选择“Evaluate&Predict”,并选择验证集 eval 进行评估。 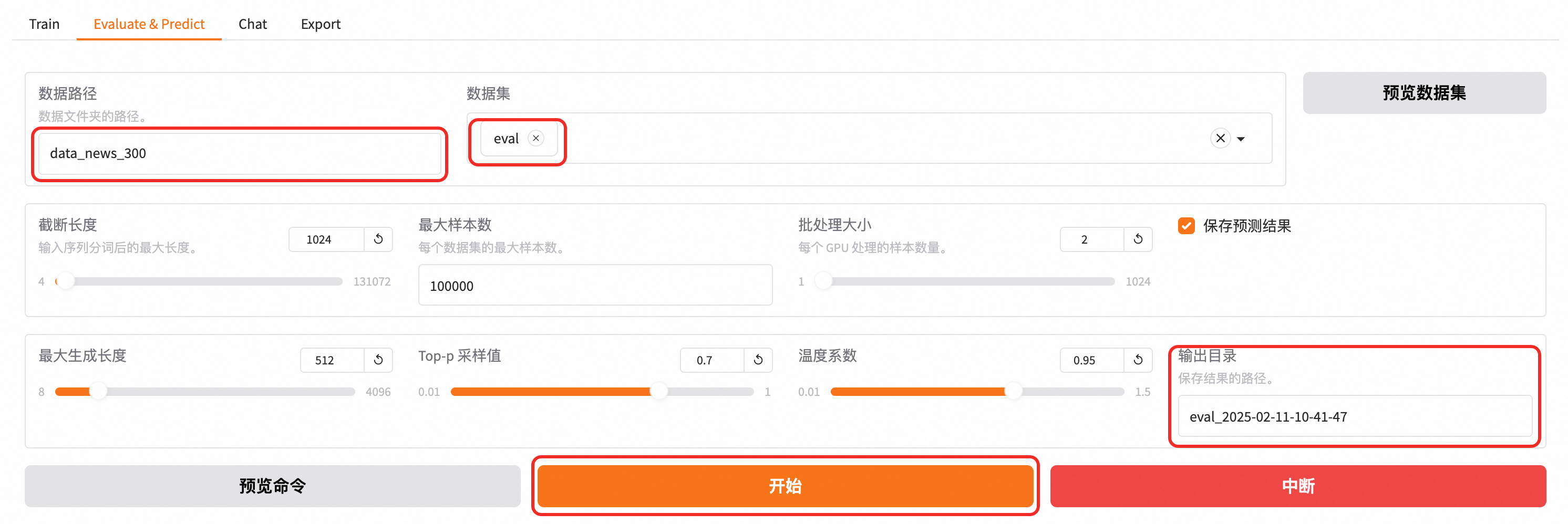
模型评估通过 ROUGE 分数来衡量输出答案与标准答案的相似度,ROUGE 分数越高,模型性能越好。
6. 模型对话
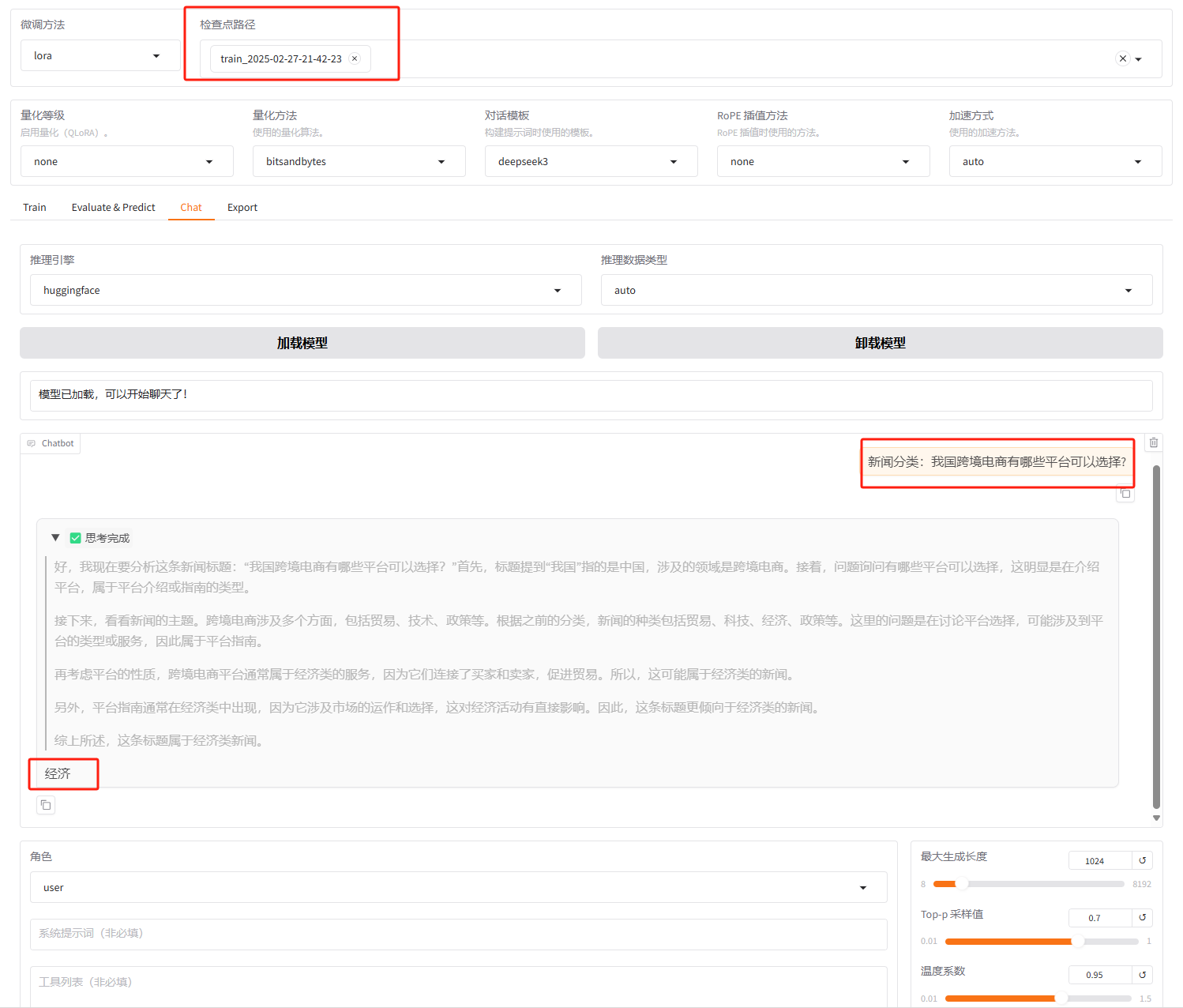
选择“Chat”选项卡,加载微调后的模型,并在对话框中输入内容。模型会按照微调后的知识进行回答,并在新闻分类任务中提供准确输出。 
在页面底部的对话框输入想要和模型对话的内容,点击「提交」即可发送消息。发送后模型会逐字生成回答,从回答中可以发现模型学习到了数据集中的内容,能够识别出用户是想对后面的标题进行新闻分类,且满足要求的输出格式,直接输出新闻分类,没有额外解释。
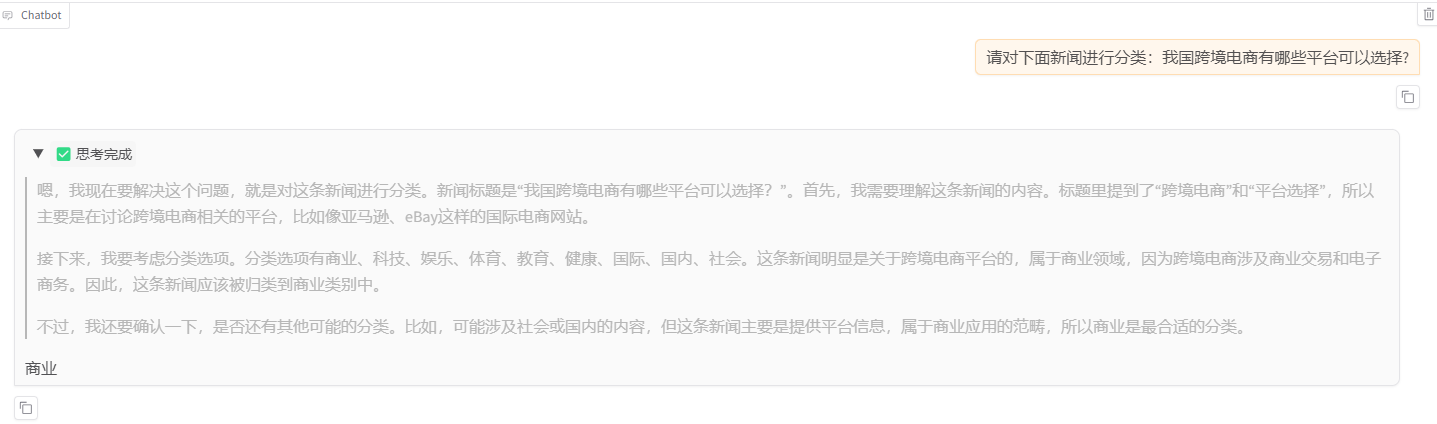
把前缀“新闻分类”改成类似的表达去询问,发现仍能满足要求。
清空历史后(避免上下文的影响),问模型其他的问题,发现其仍能正常回答,没有过拟合。
7. 总结
通过使用 LLaMAFactory 框架,结合 LoRA 微调方法,本教程演示了如何将 DeepSeek-R1-Distill-Qwen-7B 模型应用于新闻标题分类任务。通过模型训练和评估,验证了微调后的模型性能,能够根据特定数据集生成准确的新闻分类结果。
0